

Disorder, the Election, and Social Norms
Disorder does not mean wrongdoing, it means 'not in order', which requires some prior beliefs you might think about revisiting...

This is a little bit of a hot-take edition, which I try to avoid. But recent articles have touched on topics I have been chewing on, so I thought I’d throw my typewriter into the mix. Or something like that. So, some thoughts on why disorder is not part of a continuum of wrongdoing, an exploration of why horse race election polling is inexact (and disorderly, and always will be), and some scattered thoughts on changing norms and how they contribute to disorder…
The Disorder Conundrum
Charles Fain Lehman has an interesting piece on disorder that you can read here, or you can listen to the podcast with Ezra Klein here. I should say I have been chewing on this topic a lot, and for quite a while, writing perhaps a book's worth of material. Since I have little interest in scooping myself, should this project turn into something, I haven’t said much about the topic. But let me say a few words here, since folks are noodling on it.
Lehman argues that disorder and crime are not the same thing, and that even in the presence of declining crime and violence an increase in disorder can increase people’s perception that they are less safe. And that we need to police this harder, for lack of a better response. As a theory, it is groovy and intuitive. And it is hard to argue with—it’s very hard to argue with sweeping generalizations.
But let me give it a shot.
First, it is important to knock down an implicit argument here, that there is a continuum of wrongdoing, with criminality at the most serious end and disorder on the less serious end. And while proponents of this notion struggle to define disorder, what is key is that both crime and disorder are understood as elements of wrongdoing. Disorder is bad, crime is very bad, and you should not feel bad about being against disorder and wishing it would go away.
In my opinion, this shows a fundamental lack of understanding of what order and disorder are, and how they relate to crime.
Disorder is a lack of order, no argument there. Order, however, does not equate to safety. There are ordered societies all around the world and throughout time that are criminal. There are scads of ordered societies that sponsor state-sanctioned violence. That reject property rights. That subjugate human rights. That have neat hierarchies of criminality. This is corruption, and perhaps corruption is tolerable because the crimes are hidden behind an orderly façade. Or not.
Disorder is not wrongdoing. In fact, the criminal code is pretty clear when disorder is and is not wrongdoing. When disorder is wrongdoing, it is criminal. When disorder is not criminal, it is not necessarily wrongdoing. Fundamentally, I would define disorder as the organizing of people and places that are unfamiliar to others. That is, disorder is defined by current social norms. And those are inherently relative…
Second, disorder does not cause crime. This is the Broken Windows fallacy, that has been rejected over and over again by social scientists. That if a place becomes disordered, or is disordered, crime is higher than if it was ordered.
Consider the original broken windows ‘research’. Two cars are abandoned, one in a ‘good’ neighborhood, and one in a ‘bad’ neighborhood. In the ‘bad’ neighborhood, the car was ransacked in short order. In the ‘good’ neighborhood, the car was left unmolested until the researchers (THE RESEARCHERS) broke a window, and then it too was ransacked. Bebo, ergo sum, broken windows cause crime. I can’t even begin to critique that—it’s barely an anecdote, it’s certainly not science.
Third, so much of disorder is just the result of poverty or a lack of means. Poverty tends to have the effect of limiting people’s private spaces and forcing them to make public what richer people can keep private.
There is so much more. But the point is that the conclusion of the piece is essentially that we should police disorder harder. Given the points above, I would suggest something different. How about we see disorder not as wrongdoing, but instead, just see it as it is. And figure out if there is anything that could be done to help.
The Presidential Election
I wrote this before I saw the Ezra Klein had written on this topic for the New York Times this week. But his piece doesn’t really get into the mechanics of the presidential election polling and perhaps you are like me and don’t really enjoy being told things and instead want to get under the hood yourself. So let’s dig in a little.
I managed to get through college with no math or statistics. This turned out to be less of an accomplishment than it seemed at the time. Anyway, and as a result, a few years later I found myself as a new graduate student in a stats class, and befuddled. After two or three weeks in class where the waves of statistics broke over me and on me, I raised my hand and had the following exchange with my professor, or something close to it:
Me: So, we want to know some facts about a population of people?
Professor: Yup.
Me: But we can’t observe that whole population, so we draw a sample and look at that instead. And use it to draw conclusions about the whole population.
Professor: Yup.
Me: But we don’t know how well the sample represents the whole population?
Professor: Exactly.
I have little doubt I stumbled to the bar after that little exchange seeking additional clarity. And little did I know that I’d spend much of my career thinking about problems exactly like this. But this, of course, is the problem with any data that is not a census and it is exactly the problem with presidential polling data.
In election polling, we don’t know who will vote (the population). So, we don’t know how well our sample from the poll represents the population of people who will vote. We can’t know. They haven’t voted yet.
But it’s not the problem we talk about. We talk about how to put polls from different pollsters together. We don’t talk about the way that individual polls try to solve the problem I just described, one where we don’t know if our sample is representative of the population we seek to study. Instead, we doom scroll solutions to a related, but different problem—what to make of aggregators who put a bunch of these flawed polls together.
But anyway, sometimes it is helpful to return to first principles when thinking about hard problems. A lot of folks are finding the dead heat in the polls on the presidential election to be problematic, so let’s chew on that for a minute.
The presidential polling challenge, taken to brass tasks, is this. You get contact information from 10,000 randomly selected people, 1,000 people respond to the poll, 800 say they are registered voters and 600 say they are likely voters. The goal then is to weight these responses such that the 600 respondents are representative of the 150 million or so people who will actually vote. Let me unpack that a little.
The end goal of presidential election polling is to accurately estimate the outcome of the election if it were held today. It’s that last bit that makes it tricky. If all you cared about were the preferences of the electorate (registered voters), it would be relatively easy to weight the sample of people polled to match the registered voter population. Because it’s not like the problem I was asking my professor about—we actually know exactly who registered to vote. And making the sample statistically resemble a known population is pretty straightforward.

The problem is that we are asking the polls to do something else entirely. We want to know who the people who will vote, will vote for. And that’s tricky, because we don’t know who will actually vote. If you have not voted early I would suggest that even you don’t know if you yourself will actually vote. So, how do we know if the sample of people polled matches the sample of people who will vote when we don’t know who will vote?
Exactly.
The problem with the error in the New York Times graphic above is that it undersells the problem of the misses. If I put 51 people over here and 49 people over there, well, that’s a close election. But if I take just 4 people from the 49 group and add them to the 51 group, now it’s 55-45. Landslide!!
So, the whole game is about weighting each poll so the respondents reflect everyone who will vote. I could go deeply into the science of how polls are weighted. I should note here that although I work at a place that does a lot of public opinion polling I don’t actually do that work myself. But the science of weighting (often also referred to as matching) is pretty easily understood. You know what the population of people you want to generalize to looks like, so when you look at your data and see some group is underrepresented in your data, you give them bigger weights. When they are overrepresented, you give them smaller weights.
But what do you do when you don’t know exactly what the population you want to generalize to looks like? Well, you try to reduce your uncertainty.
There are three general strategies to weight data in the presence of uncertainty.
Look at the data you had about age, race, gender, geography, etc. of past voters and weight your sample to look like that.
Look at your own sample of respondents who say they are likely to vote compared to those who are registered to vote but don’t say they are likely to vote, and use what you know about them, (age, race, gender, geography, etc.) and to reweight your own sample.
Do a mix of both strategies.
Now, you can see the problem already. If there are changes in the electorate from past elections—that is, if there are unexpected changes in who actually votes on or by Election Day, it is easy to make mistakes. And there is every reason to believe that the mix of voters this year will be at least a little different. For one thing, we might be on the precipice of electing the first female president! And the first president of South Asian descent! And more! That is certainly likely to change the electorate at least a little. Plus, there are new voters who just came of age. And last election voters who are no longer with us. And all the continuing voters are four years older. And you get the idea…
The point of all of this is that we can’t know prospectively how well the polls are accounting for these changes. We can only know retrospectively, and then only partially.
Plus, I want to point out that the problems that Nate Silver and the other poll aggregators are working on are different than the problems I describe above. The problem they are working on is how to weight polls by who conducts the poll. They want to give higher weights to more scientific, nonpartisan polling outfits. That’s great!
But its an indirect way to solve the problem I describe. Since we can only know after the fact whose weighting scheme was sound and whose was not, it is hard to know whether these additional weights by the polling aggregators solved problems or made them worse. If they are all doing it roughly the same way and they are all roughly right, then the aggregators will do a good job.
I wonder. What I wonder about in particular is whether the stability of the topline results—a near draw between Harris and Trump that has held steady—is misleading pollsters into thinking they solved the problem. A humble approach would dictate that stability is really telling you very little.
None of this is a new problem. This is not really even a solvable problem—it’s an endogeneity problem where more of the same data gets you no closer to an answer. We will only know the answer after the election (and even then, we will only sort of know the answer). Will the pollsters get it right?
As my kid would say, mayhaps.
Must Read
I was delighted to see this article in the Conversation exploring why crime fell so sharply in Philadelphia. While I obviously appreciate the author’s kind words, what I really appreciate here is that there does not appear to be any ideology at play—it is a straightforward analysis that focuses on the facts as we have them. This kind of clear-eyed analysis is pretty rare these days, even though it is exceptionally important. I would love to see this kind of after-action review in every city. The community violence decline appears to be widespread, but highly variable. The national trends matter, but as the authors point out here, they are only one piece of the puzzle. A lot of the puzzle is about understanding what a community is—and isn’t doing.
Snapshot
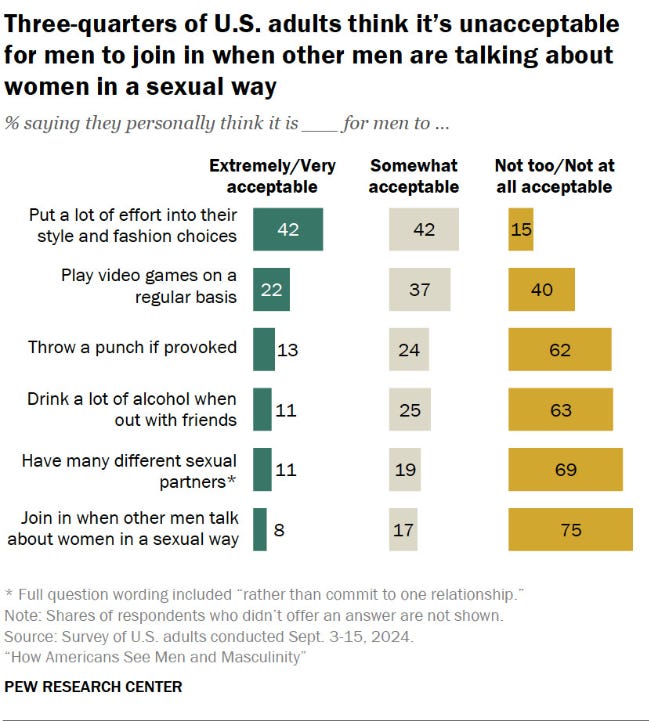
I am generally not a fan of generational analysis. I’m Gen X so I’m this way, you are a Millennial so you are that way, Boomers are bad, Gen Z is lost, blah, blah, blah. What I am interested in though is when social norms shift because it reminds us that what is not allowed today (to bring it back home, what is disorder today) may well be normative tomorrow. Dara Lind makes this point succinctly about changes in parent-child relationships, and John Gramlich makes it as well with Pew Research with new data on traditionally ‘acceptable’ male behavior.

Musical Interlude
Yo, I need a break from the rage-advertising that dominates all my Pennsylvania media. Lord. Let me offer a couple of antidotes.
For your head, here is Noah Smith on the glorious state of the US economy, wherein he channels Sundown from Top Gun who says to Maverick, “What do you mean, ‘it doesn't look good’? It doesn't get to look any better than that!” And Matt Yglesias on why the commonly cited statistics on a majority of Americans living paycheck to paycheck are bunk.
For the rest of you, there’s this. We saw these guys the other day and it was … nice. Warm. Totally free of any dystopian madness. What a concept.
Thanks for addressing Lehman…I was so irritated.
You unequivocally are correct based upon your definition of disorder. However, my understanding of “Broken Windows” is acting to enforce penalties, as opposed to ignoring, low-penalty crimes. The argument for such enforcement can be extended to California’s decision to make shop-lifting low-penalty. A reference to some studies that disprove the positive effects the application of the policy in NYC will be helpful.